Sounddesign: Schlechte Radio- und Funkübertragungen simulieren
von Klaus Baetz, Artikel aus dem Archiv
Anzeige
(Bild: Klaus Baetz)
Stimmen aus einem Radio- oder Funkgerät, gerade solche von schlechter Qualität, sind immer wieder ein regelmäßig notwendiger Effekt. Wer über eine entsprechende Funkanlage verfügt, kann dann auch diese zur Aufnahme solcher Sounds verwenden. Alle anderen müssen sich den Effekt selbst bauen. Wie das aussehen könnte, schauen wir uns in dieser Sounddesign-Folge an.
Unser gewünschter Sound besteht aus zwei grundlegenden Komponenten: der eigentlichen Sprachaufnahme sowie den Störgeräuschen wie Rauschen, Brummen, Fiepsen etc. Beides müssen wir getrennt voneinander behandeln, damit wir beide Signale anschließend möglichst nahtlos zusammenmischen können, denn das Ergebnis soll ja so klingen, als wäre es aus einem einzelnen Gerät gekommen. Wir erzeugen in unserer DAW also zwei Audiospuren, die wir anschließend zur gemeinsamen Bearbeitung auf eine Gruppe routen.
Anzeige
Die Sprachaufnahme
Für das Basismaterial unserer Sprachaufnahme müssen wir ein paar Punkte berücksichtigen. Im Gegensatz zum gewünschten Endergebnis, sollte die Sprachaufnahme möglichst sauber und trocken sein. Allzu starke Raumanteile müssen wir ebenso vermeiden wie Noises oder Grundrauschen jeglicher Art.
Man könnte nun natürlich diese Aufnahme auch mit einem Mikrofon durchführen, was an sich schon kaputt verzerrt klingt, sei es durch eine Beschädigung am Mikro selbst oder schlicht deswegen, weil das Gerät qualitativ schlecht ist. Wer sich dabei sicher fühlt, kann sich so eventuell etwas Zeit ersparen, nimmt sich aber gleichzeitig auch die Flexibilität. Daher ist hier meiner Ansicht nach der beste Ansatz, die Aufnahme wie jede andere ordentliche Sprachaufnahme zu betrachten, auch wenn das Ergebnis nicht mehr danach klingt.
Wer möchte und über entsprechende Hardware verfügt, kann das Signal auch gerne schon während der Aufnahme ein wenig komprimieren und verdichten. Gerade wer eine Radioübertragung simulieren möchte, braucht dazu auch die passende Radiostimme, und da ist Kompression ein extrem wichtiger Bestandteil. Zum späteren Feintuning komprimieren wir das Signal nochmal innerhalb der DAW.
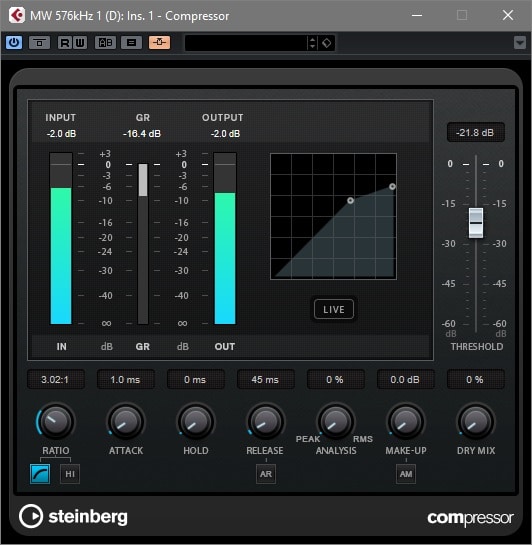
Mit einem Kompressor werden die Störgeräusche leicht weggeduckt, was die Stimme besser in den Gesamtsound integriert.
Das analoge Radio
Nachdem die Sprachaufnahme im Kasten ist, widmen wir uns der zweiten Komponente unseres Sounds. Dafür benötigen wir ein klassisches analoges Radio, bestenfalls eines, welches nicht nur UKW, sondern auch Lang-, Mittel- und Kurzwelle empfängt. Ein separater Line-Out wäre ebenfalls schön, aber auch ein Kopfhörerausgang funktioniert. Nun beginnt die große Suche nach Störgeräuschen.
Gerade wenn das Radio über einen breiten Frequenzgang verfügt, kann man hier Stunden mit der Suche nach Geräuschen verbringen, wenn man nicht zwischendurch immer mal wieder von Musik, kryptischen Stimmen und anderen geheimnisvollen Signalen abgelenkt wird. Hier findet man einen gigantischen Fundus an spannenden Sounds. Wenn wir beim langsamen Sweepen durch das Frequenzband schließlich auf ein interessantes Störgeräusch gestoßen sind, sollten wir davon ruhig mindestens eine Minute aufnehmen. So verfügen wir über genügend Material, um die Aufnahme eventuell zu loopen.
Signalbearbeitung
Nachdem nun beide Aufnahmen den Weg in unsere DAW gefunden haben, können wir die beiden Signale anpassen und möglichst überzeugend verschmelzen. Die Spur der Sprachaufnahme versehen wir dazu mit einem Kompressor nach Wahl, um das Signal passend zum gewünschten Ergebnis zu verdichten. Wie bereits erwähnt darf hier, gerade wenn es sich um eine Radioübertragung handeln soll, durchaus auch härter zugegriffen werden. Anschließend fügen wir einen EQ in die Spur ein, mit dem wir zunächst mit einem Low-Shelf-Band den Bassbereich etwas absenken. Auch in den Höhen kann eine leichte Absenkung, je nach Mikrofon, nicht schaden.
Abschließend benötigen wir noch einen Distortion-Effekt, um unserer so wunderbaren Stimme nun die notwendigen Verzerrungen zu verpassen. In meinem Falle habe ich dafür mal wieder den Steinberg QuadraFuzz 2 verwendet. Als Settings bin ich auf Singleband gegangen, habe den Dist-Algorithmus gewählt, Drive auf 0,2 geschoben und Feedback auf 100 %. In Abstimmung mit unserem Verzerrer können wir beim vorgeschalteten EQ auch noch ein Mittenband aktivieren, mit dem wir der Stimme per Boost einen leicht nasalen Touch verleihen. Gleichzeitig kann dadurch auch die Verzerrung noch ein wenig aggressiver klingen.
Widmen wir uns parallel unseren Störgeräuschen: Auch hier fügen wir zunächst einen technischen EQ in den Signalweg ein, mit dem wir das Rauschsignal ein wenig aufräumen. So ist das dezente Absenken der Bässe in der Regel durchaus sinnvoll. Dem Höhenbereich sollten wir ebenfalls Beachtung schenken und diesen, je nach Grundmaterial, ein wenig anheben oder absenken.
Anschließend schleifen wir einen Kompressor in unsere Audiospur ein, welche wir mit einem Pre-Fader-Signal unserer Stimme beschicken. Anschließend schalten wir sämtliche Automatikfunktionen des Kompressors aus, wählen eine sehr kurze Attack- und eine recht kurze Release-Zeit, stellen die Ratio auf 3:1 und reduzieren den Threshold nach Geschmack. Unser Rauschen wird nun immer wieder von der Stimme dezent weggeduckt. Dabei sollte der Effekt allerdings subtil sein und nicht wie das Wegducken von Musik durch eine Sprecherstimme klingen.
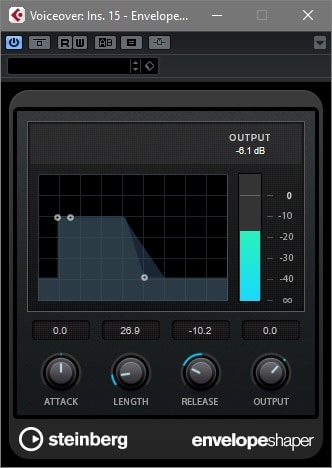
Mit einem Transienten Deisgner/Envelope Shaper lassen sich Wortteile unterdrücken, um somit eine schlechtere Sprachübertragung zu simulieren.
Summenbearbeitung & Feintuning
Nachdem nun beide Einzelsignale in eine gemeinsame Gruppe geführt wurden, müssen wir durch Anpassung der Channel-Fader sowie Feintuning des Kompressor-Thresholds dafür sorgen, dass die Stimme sich möglich gut in den Teppich aus Störgeräuschen bettet. Sobald hier ein gutes Verhältnis gefunden wurde, können wir dann mit einem weiteren EQ auf der Gruppenspur noch eine Anpassung des Gesamtsounds vornehmen. Ich persönlich habe hier Bässe und Höhen nochmal leicht abgesenkt, um das Signal somit mittiger erklingen zu lassen, gleichzeitig sind die beiden Komponenten dadurch auch noch besser verschmolzen.
Wer das Signal nun noch weiter verschlechtern will, dem stehen natürlich alle Möglichkeiten an Effekten offen. Eine simple, aber effektive Methode, die Sprachverständlichkeit zu verschlechtern und den Sound so wirken zu lassen, als ob immer wieder Sprachfetzen verloren gehen, möchte ich noch kurz demonstrieren. Dazu laden wir einen Transient Designer in einen Post-Fader-Insert-Slot (wichtig, da wir den Send zum Kompressor-Sidechain nicht beeinflussen wollen) der Sprachspur. Anschließend können wir einfach den Release-Parameter langsam herunterregeln, und als Resultat werden immer mehr Wortteile unterdrückt. Wer über keinen Transienten Designer verfügt, kann alternativ auch ein Gate verwenden, was aber ungleich schwieriger einzustellen ist. Viel Spaß beim Experimentieren!







Tolle Anleitung und prima Ideengeber. Danke